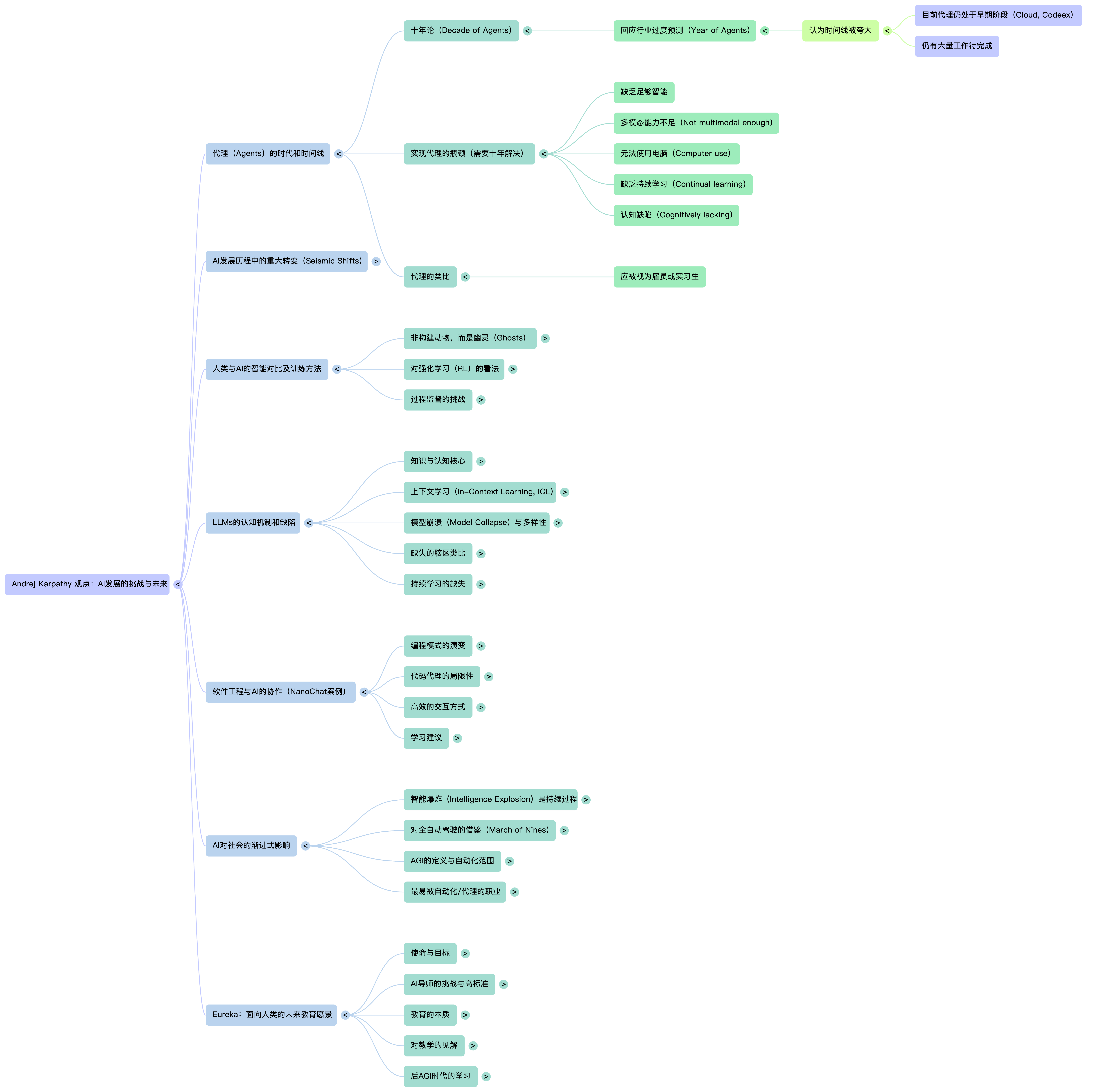
Andrej Karpathy(AK)提出 AI 智能体(Agent)的时代将是“十年之期”,而非“一年爆发”,是对行业内一些实验室过度预测(“智能体之年”)的直接回应。他承认目前已经存在一些“令人印象深刻的”早期智能体,例如 Claude 和 Codex,但他认为要实现真正的、具有实用价值的智能体,仍有大量艰巨的工作要做,这个时间跨度需要大约十年。
Karpathy 的预测基于他近 15 年的 AI 行业经验和直觉推断。他认为,虽然这些问题是可解决的(tractable),但它们本质上是困难的,需要一个漫长的过程来克服。
核心论点一:理想智能体的“认知”缺陷与技术瓶颈
Karpathy 设想的理想智能体,应该像一个你可以雇佣的员工或实习生。然而,他列举了当前智能体存在的诸多“认知缺陷”和能力瓶颈,正是这些缺陷决定了“十年”而非“一年”的时间表。
| 缺陷/瓶颈 | 具体含义与影响 | 来源 |
|---|---|---|
| 缺乏足够的智能 (Lack of Intelligence) | 智能体在处理独特、非样板化、需要精确安排的知识密集型任务时表现不佳,常常误解定制代码,或倾向于引入不必要的复杂性。 | |
| 缺乏多模态 (Not Multimodal Enough) | 智能体目前主要基于文本工作,难以处理视觉、图形等多种模态的信息。例如,相比处理代码(本质上是文本),让智能体处理幻灯片(涉及图形和空间排列)要困难得多。 | |
| 无法使用计算机 (Cannot Do Computer Use) | 智能体缺乏与计算机环境(如操作系统、浏览器)进行高效交互的能力。 | |
| 缺乏持续学习能力 (Lack of Continual Learning) | 大语言模型(LLMs)每次启动时,都像是从头开始(零上下文)。它们缺乏类似人类睡眠中的“蒸馏”阶段,无法将上下文窗口中获取的新信息有效地整合并固化到权重中,以实现长期记忆和知识保留。 | |
| 认知上的不足 (Cognitively Lacking) | 当前的模型仍存在许多“认知缺陷”。例如,它们缺乏对人类大脑中古老核团(如杏仁核、基底神经节)所代表的情感和本能的模拟,尚未完全具备像人类那样进行推理和规划的能力。 |
核心论点二:从“试错”中吸取教训——表征能力先于智能体
Karpathy 认为 AI 历史中有过多次“地震式转变”。其中,早期的智能体尝试——例如 2013 年左右基于 Atari 游戏的深度强化学习(DRL),以及他自己在 OpenAI 参与的 Universe 项目(旨在让智能体使用键盘和鼠标操作网页)——最终都被他视为“失误”(misstep)。
失败的原因在于:
- 奖励信号稀疏: 在尝试通过键盘和鼠标点击网页来获取奖励时,奖励信号太过稀疏,导致模型难以学习。
- 缺乏表征能力: 当时的神经网络缺乏表征能力(power of representation)。模型在环境中摸索,盲目尝试,消耗了巨大的计算资源,却无法取得进展。
正确的路径(LLM 的兴起):
Karpathy 认为,实现更好的智能体,必须先通过预训练(pre-training)来获得语言模型和强大的表征能力。只有站在大语言模型提供的强大认知基础上,才能继续训练那些能使用计算机、解决实际问题的智能体。
核心论点三:部署的“九的行进”与高失败成本
即使技术难题被解决,将 AI 智能体部署到对可靠性要求极高的真实世界任务中,也需要漫长的时间,这被称为“Demo 到产品”的巨大鸿沟。
Karpathy 借鉴了自动驾驶(他在特斯拉领导了五年)的经验来预测智能体部署的速度。
- “九的行进”(March of Nines): 要达到真实世界所需的可靠性(例如 99.9999%),每增加一个“九”的可靠性都需要付出巨大的努力。一个 Demo 可能很容易达到 90% 的成功率,但要达到 99% 或更高,则需要数年的迭代。
- 高失败成本: 在如自动驾驶和生产级软件工程等领域,失败的成本太高。
- 在自动驾驶中,失败可能导致人身伤害。
- 在软件工程中,错误可能导致安全漏洞或数据泄露,后果同样可能是“无上限的糟糕”。
- 渐进式自动化: 在实际工作中,不会出现“一夜之间”的全面替代。AI 的影响是一个自主性滑块(autonomy slider)的过程,人类逐渐从低级工作中抽象出来,将更多的任务自动化。
- 例如,在呼叫中心,AI 可能会处理 80% 的常规请求,而将 20% 的困难情况委派给人类,让人类监督 AI 团队。
核心论点四:当前算法的局限性
Karpathy 尤其批评了当前智能体训练中普遍使用的强化学习(RL)方法,他认为这是导致智能体发展缓慢的关键技术障碍之一。
- RL 的“糟糕”本质: Karpathy 直言不讳地指出,强化学习是“糟糕的”(terrible),尽管它比过去的方法好得多。
- “通过吸管吸取监督信息”: RL 的核心问题是奖励信号过于稀疏且具有高方差。当智能体完成一个复杂任务后,最终的奖励信号会被“广播”到整个行动轨迹中的每一个标记(token)。他生动地比喻这就像“通过吸管吸取监督信息”。模型会错误地加权整个轨迹,包括那些导致错误的中间步骤。
- 缺乏过程监督: 理想情况下,模型需要基于过程的监督(Process-Based Supervision),即在每一步都能得到反馈。然而,实现自动化的部分信用分配非常困难。使用 LLM 裁判来评估过程监督容易受到对抗性攻击(adversarial examples)的干扰,导致模型发现作弊的方法,分配 100% 的奖励给毫无意义的输出。
总结
Karpathy 坚持“十年之期”而非“一年爆发”,源于他对行业炒作的警惕,以及他对实现真正的、可信赖的通用智能体所必需的认知能力、持续学习机制、鲁棒的 RL 算法,以及在风险高昂领域中达到生产级可靠性(March of Nines)所需时间的冷静评估。他认为,虽然 AI 正在经历一场智能爆炸,但这是一种持续了几十年的趋势,其社会影响将是渐进的,缓慢扩散的,而不是一个突然的离散事件。